Use case 的第二篇讓我們繼續「盜竊」,這次的目標是 Jaeger 的 Service Performance Monitoring(SPM)。
Jaeger 是 Uber 於 2015 年開源的分散式追蹤(Distributed Tracing)工具,在 Tracing 領域中是非常成熟的專案。Jaeger 的主要開發者 Yuri Shkuro 一直致力於 Tracing 領域的發展,他也是目前主流的 Trace 規範 OpenTelemetry 的 Co-founder 之一。
如同前面章節提到的,OpenTelemetry 涵蓋了各種語言的 SDK 以及資料處理工具 OpenTelemetry Collector。Jaeger 的 SPM 就是應用了 OpenTelemetry Collector 中的 Span Metrics Connector 打造而成。Span Metrics Connector 能夠從 Trace 資料中計算 RED Metrics,當這些 Metrics 被 Prometheus 採集後,Jaeger 就可以透過 Prometheus 查詢並將其顯示在 UI 上。
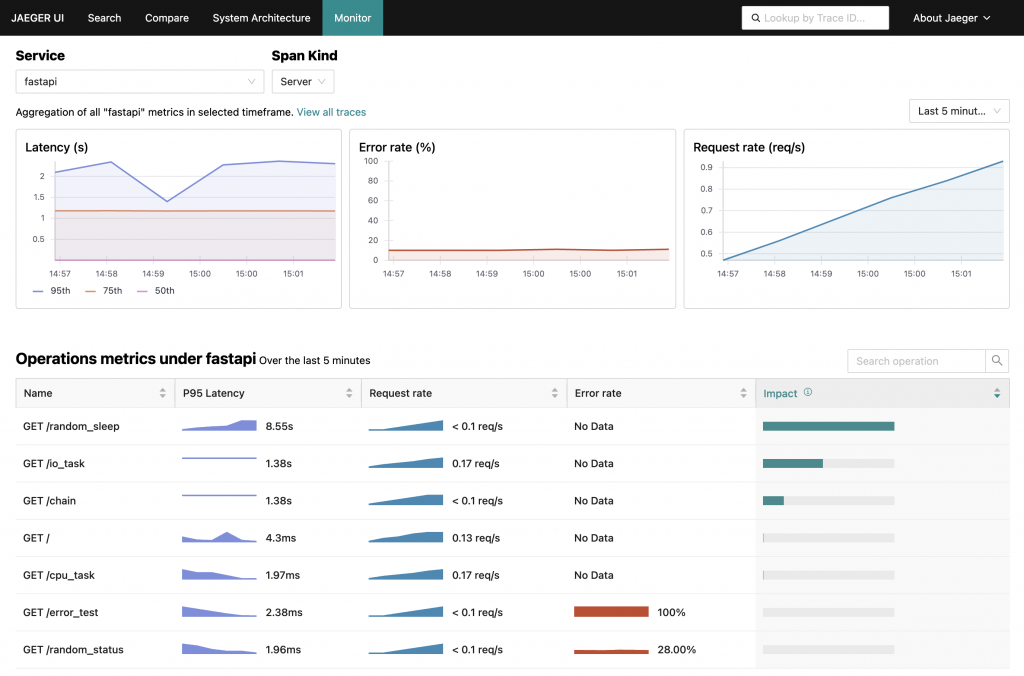
在 SPM 的 UI 中,可以根據不同的 Service 和 Span Kind 查詢資料。其中的 Server Span Kind 會記錄該服務處理的 Request 資訊,這也是通常第一步會想監控的內容。
UI 主要分為三個結構:
Jaeger SPM 架構如下:
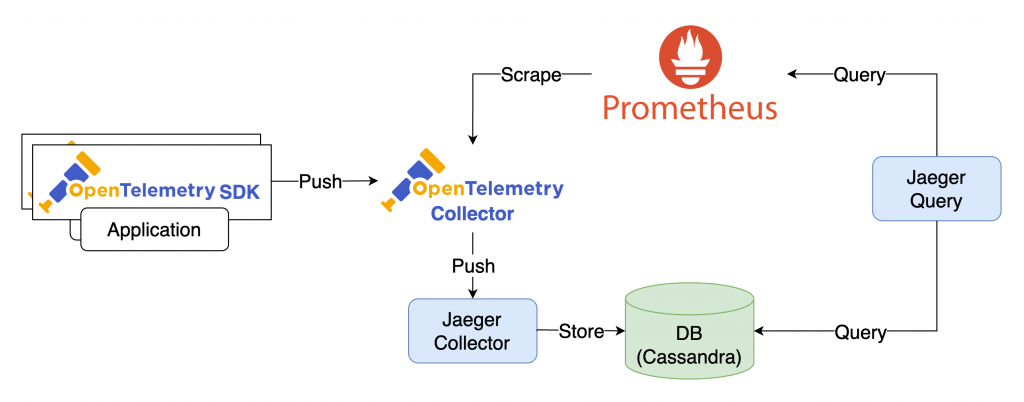
/metrics endpoint 上揭露。從架構圖中可以發現,SPM 的內容主要基於 Prometheus 中的 Metrics。所以我們只要使用相同的 Metrics,就有機會仿造出一樣的功能。
在 Jaeger SPM 中,與 Metrics 有關的元件主要是 OpenTelemetry Collector 和 Prometheus。因此,我們可以捨去 Jaeger 相關元件,並使用 Grafana 來查詢 Metrics。不過,為了方便檢視 Trace 資訊,我們可以引入 Tempo 來負責 Trace 的儲存。
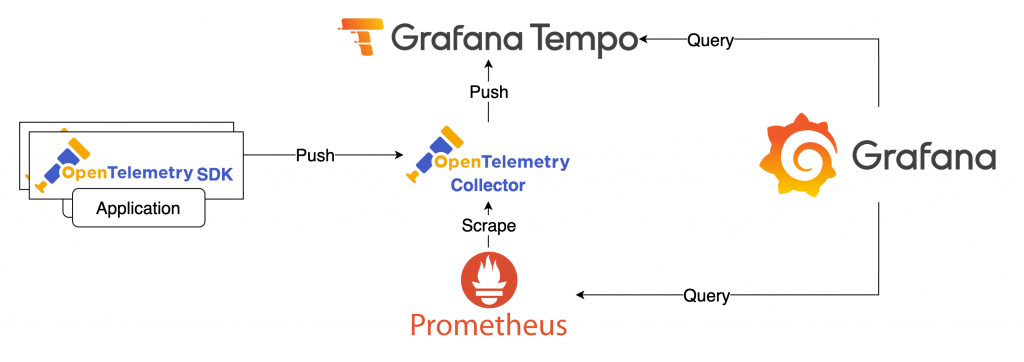
仿造 Jaeger SPM,我們使用 Span Name 和 Span Kind 作為 Variable,提供選單供切換。後續的查詢都基於這兩個 Variable 進行篩選。
在 Prometheus Metrics 中,通常會使用 Histogram 來儲存數值分布資訊,Latency 或執行時間就是其中一個常用目標。對於這類時間資訊,我們通常更關注不同百分位數的數值,而非容易失真的平均值。
Histogram 指標由三種資料組成:各個區間的計數(Bucket)、總和(Sum)和總計數(Count)。Bucket 負責計數,它的指標名稱後綴為 _bucket,且會帶有一個 le Label 來表示該 Bucket 的上限。例如,以下是計算執行時間秒數的 Histogram 指標 request_process_time:
request_process_time_bucket{le="0.1"} 5:執行時間小於等於 0.1 秒的有 5 筆request_process_time_bucket{le="0.5"} 15:執行時間小於等於 0.5 秒的有 15 筆request_process_time_bucket{le="+Inf"} 30:執行時間小於等於無限大的有 30 筆查閱 OpenTelemetry Collector 的 Metrics Endpoint,可以發現紀錄 Latency 的 Bucket 指標為 traces_span_metrics_duration_milliseconds_bucket。接著透過 Prometheus 的 histogram_quantile 函數,我們可以計算出不同百分位數的 Latency。例如,計算 Service fastapi 在過去三分鐘內的 95% 百分位數 Latency 的語法為:
histogram_quantile(0.95, sum(rate(traces_span_metrics_duration_milliseconds_bucket{service_name="fastapi"}[3m])) by (le))
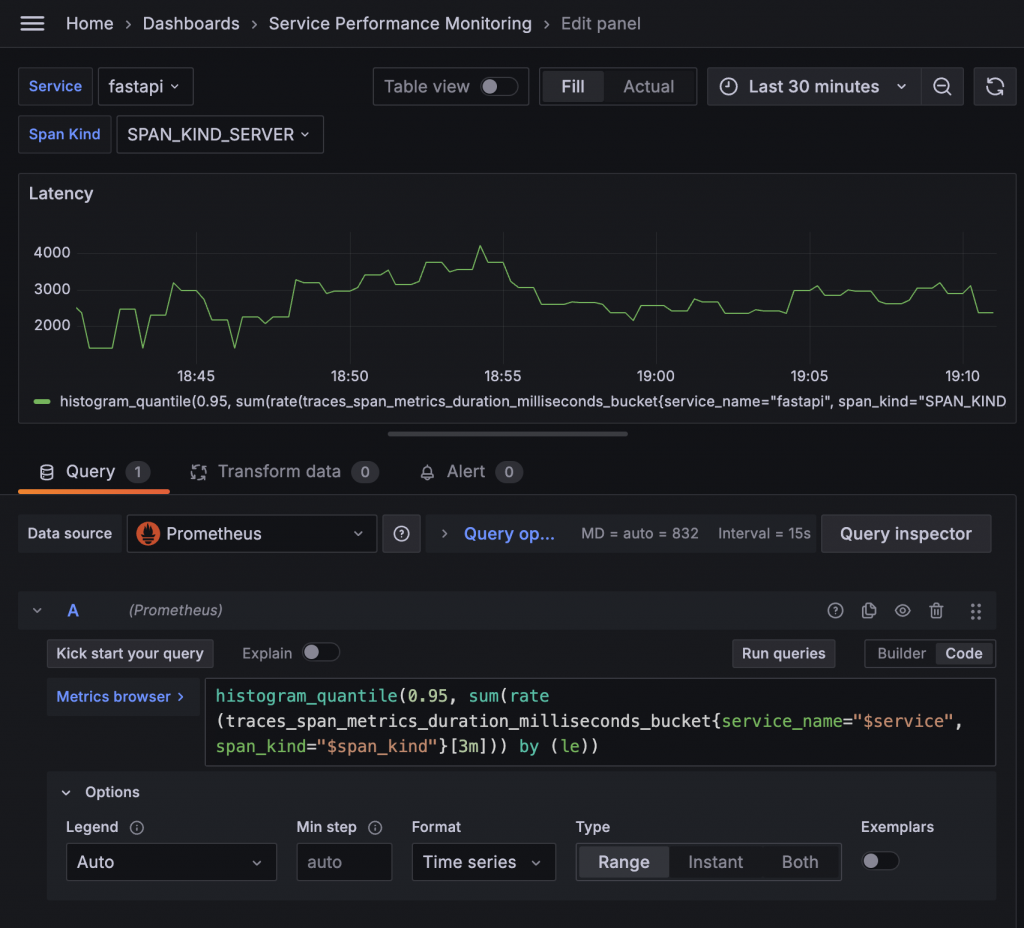
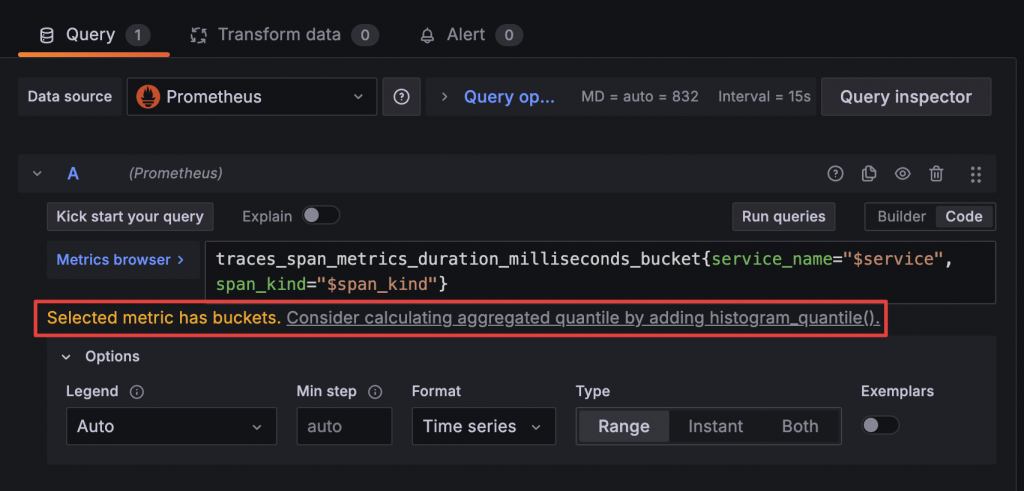
這個語法看起來可能有些複雜?別擔心,Grafana 會在你查詢 Histogram 的 bucket 指標時自動提示你是否想要計算百分位數。只需點選建議,Grafana 就會自動填入公式,只需要再依照需求微調即可。
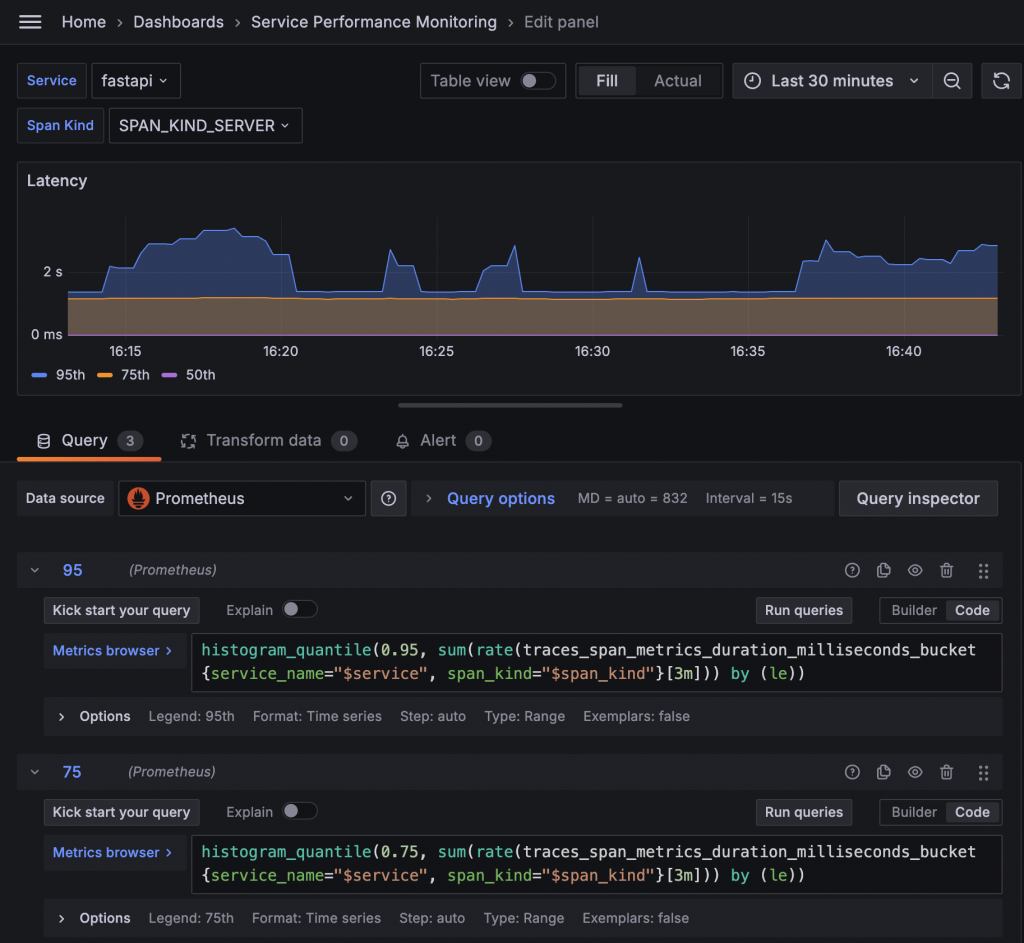
透過 Histogram 的 bucket 指標與 histogram_quantile 計算,我們可以得到 PR95、PR75 和 PR50 的 Latency 數值。
在 Metrics 中,我們可以發現 traces_span_metrics_calls_total 指標的 status_code Label 中包含 STATUS_CODE_ERROR。要計算錯誤率,我們可以將篩選 status_code="STATUS_CODE_ERROR" 的數據總和,除以未篩選的總和,來計算出錯誤率。
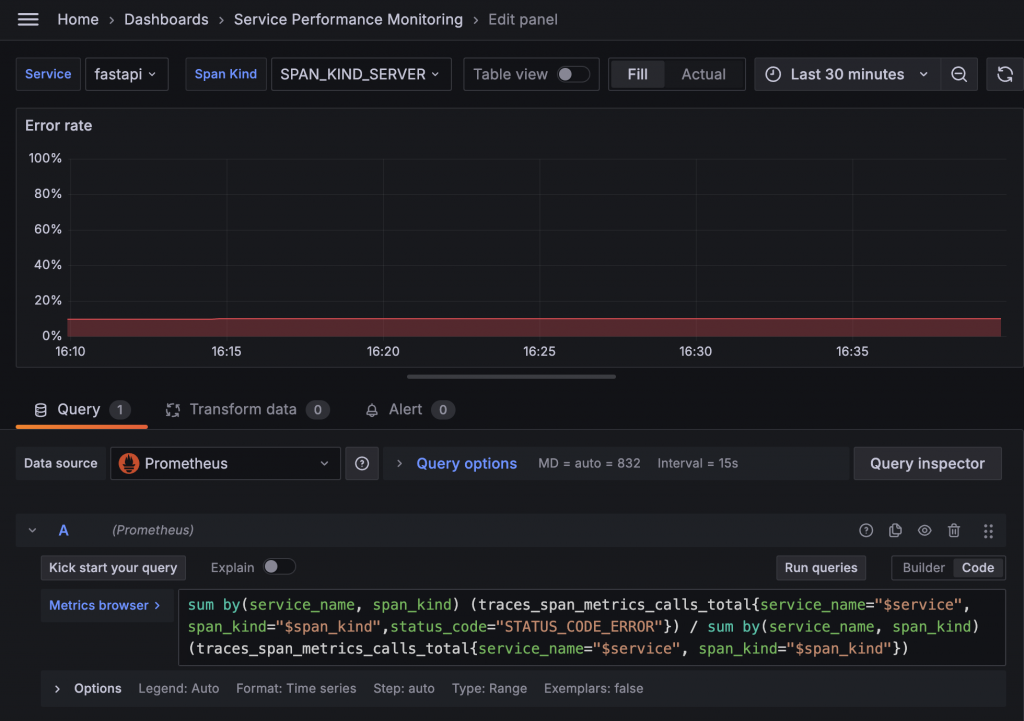
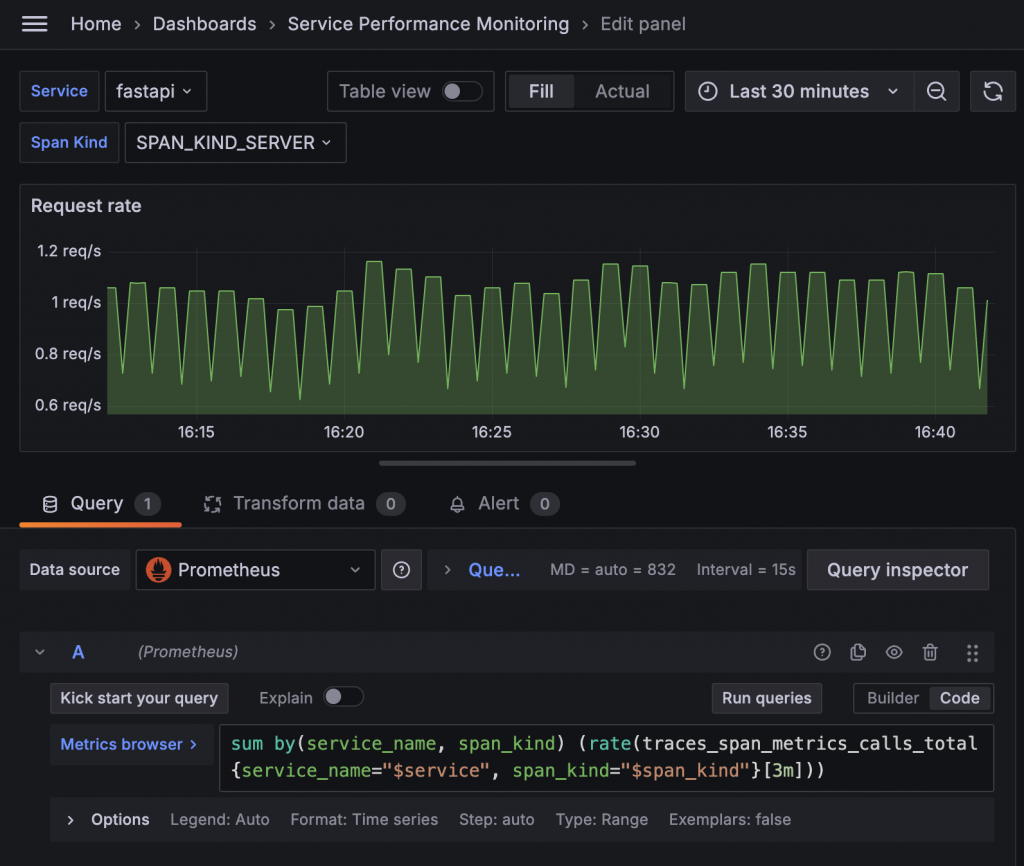
traces_span_metrics_calls_total 這個指標同時也紀錄了執行次數。我們可以使用 Prometheus 的 rate 函數來計算其變化率,這就是我們想要的 Request rate。例如,以下語法可以計算 Service fastapi 在過去三分鐘內的 Request rate:
sum(rate(traces_span_metrics_calls_total{service_name="fastapi"}[3m]))
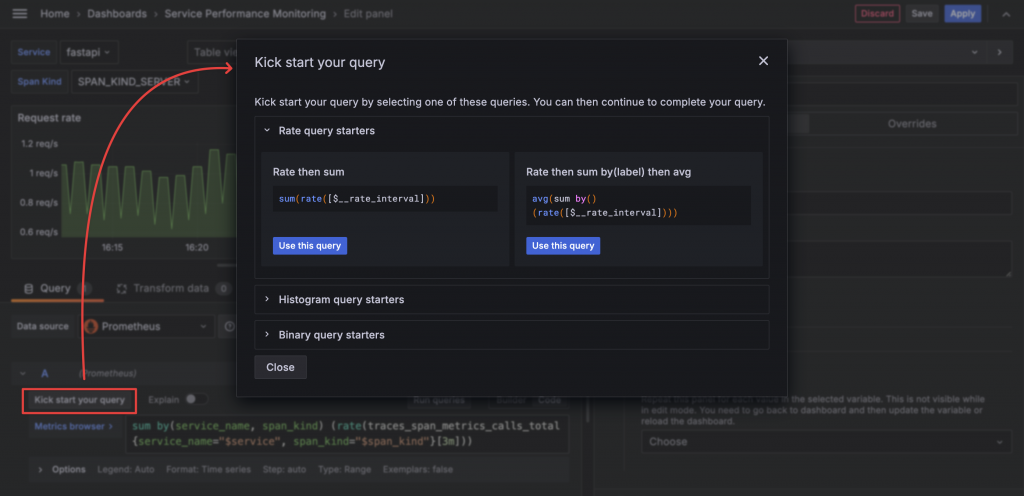
如果你忘記了語法,例如先 sum 再 rate 的規則,可以點擊 Query 語法欄上方的 Kick start your query,其中會提供 Prometheus 常用的語法小抄與說明。
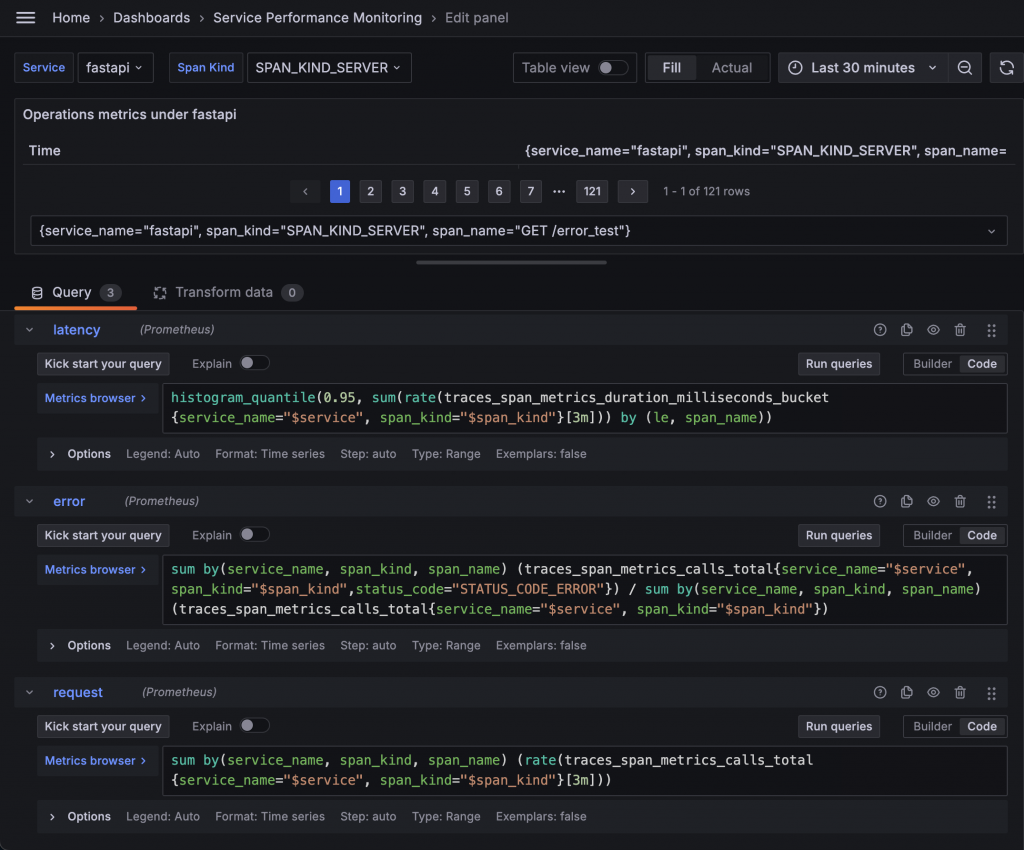
細項表格中要呈現的資料與前面的 Latency、Error rate、Request rate 基本上一致,但需要多拆分一組由 HTTP Method 與 Path 組成的 Span Name。所以我們可以先直接複製前面的 Query 到 Table Panel 中。
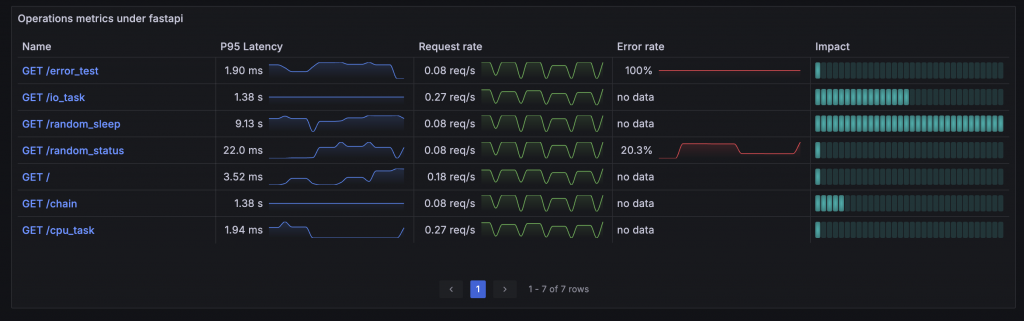
Jaeger SPM 的表格不僅顯示了 RED Metrics 的數值,還繪製了小型折線圖,這種表格中的小圖表稱為 Sparkline。在 Grafana 的 Table Panel 中,將 Cell type 設定為 Sparkline 就能啟用,但這需要搭配 Time series to table transform,將時間序列資料轉換為 Table 所需的格式。
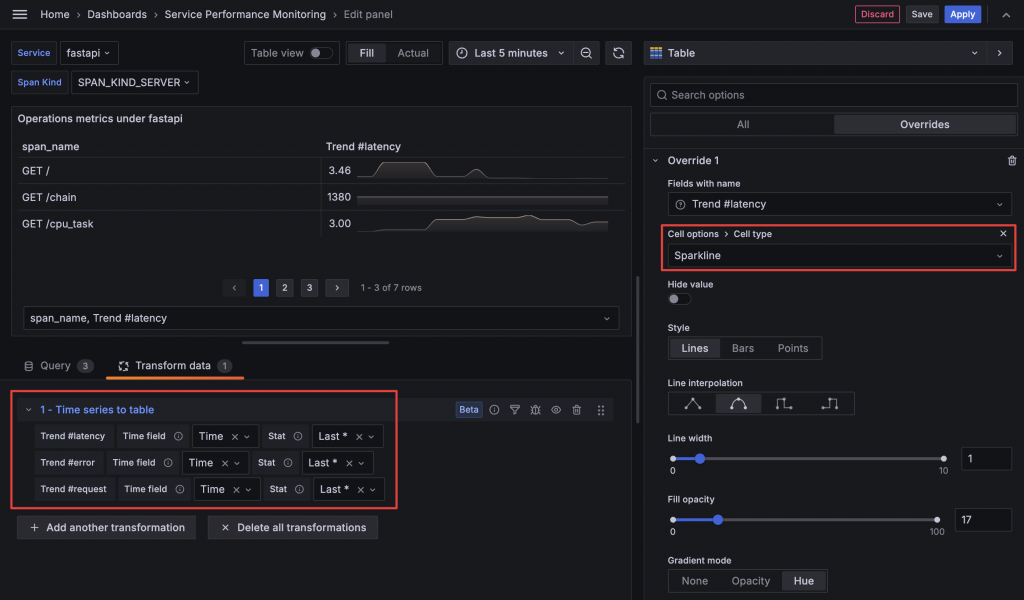
目前三組數據還是各自獨立在不同的 Frame 中,因此我們需要使用 Merge series/tables 來合併它們。
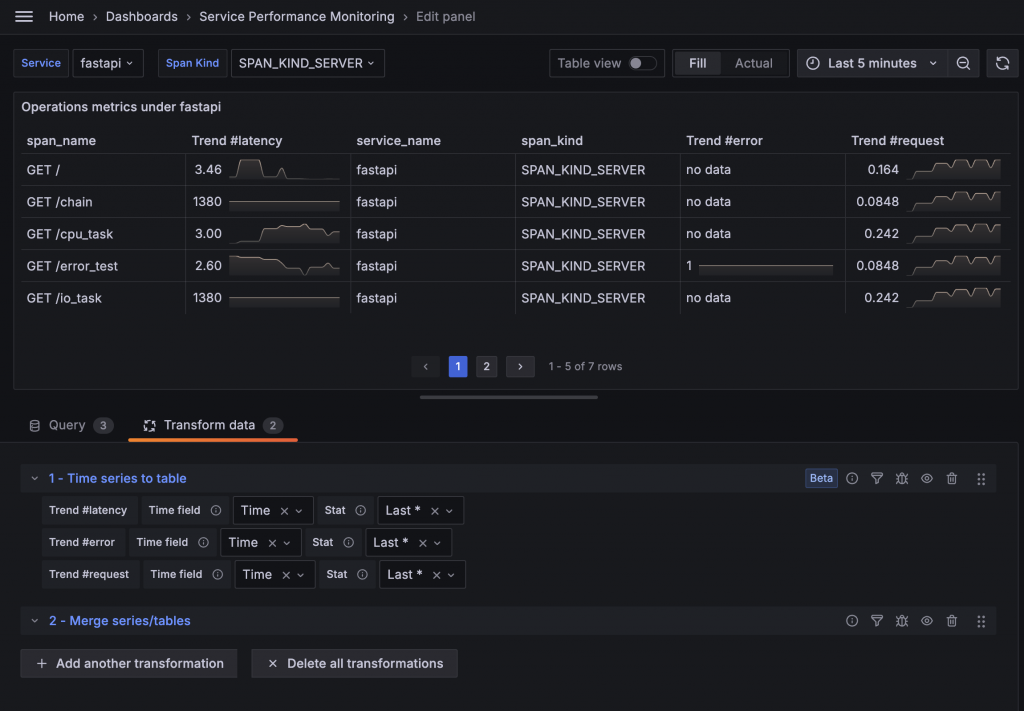
接下來是 Impact 指標。根據 Jaeger 的文件說明,這個指標是將 Latency 和 Request Rate 相乘而得。因此,我們可以直接將前面的 Query 相乘來計算 Impact。
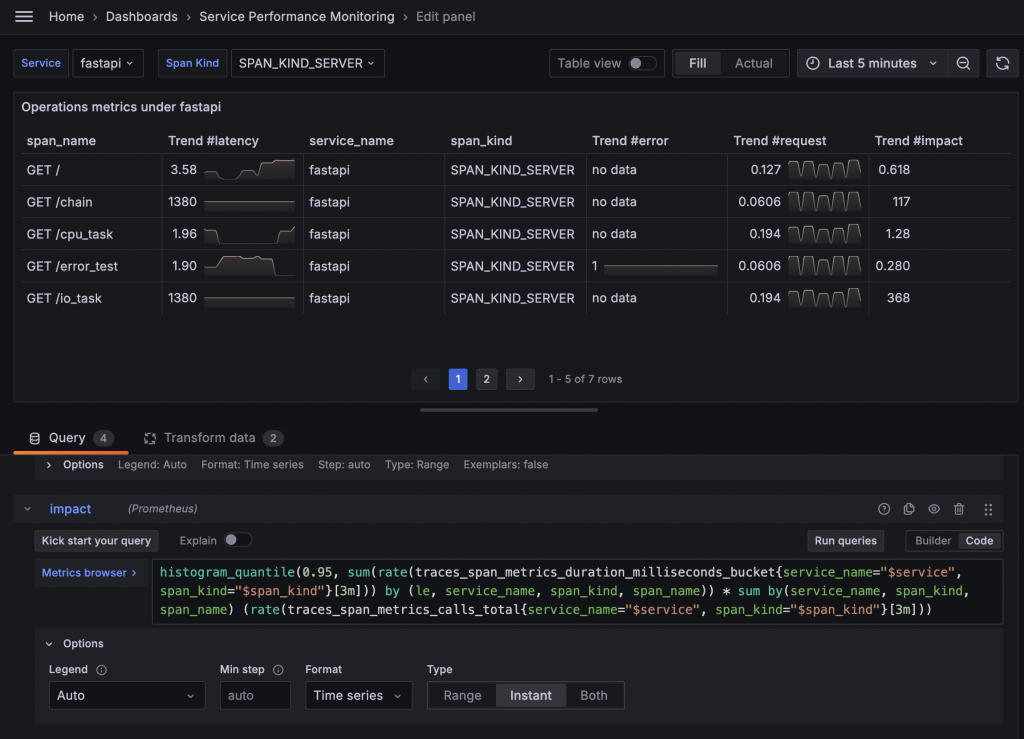
最後一個功能是 View Traces 的連結功能,點擊後可以直接查詢該 Span Name 的 Trace。我們可以使用 Data Link 將連結加在 Span Name 上,並利用前面設置的 Tempo,將 Service Name 和 Span Name 傳遞到 Tempo 的 Explore URL 中。
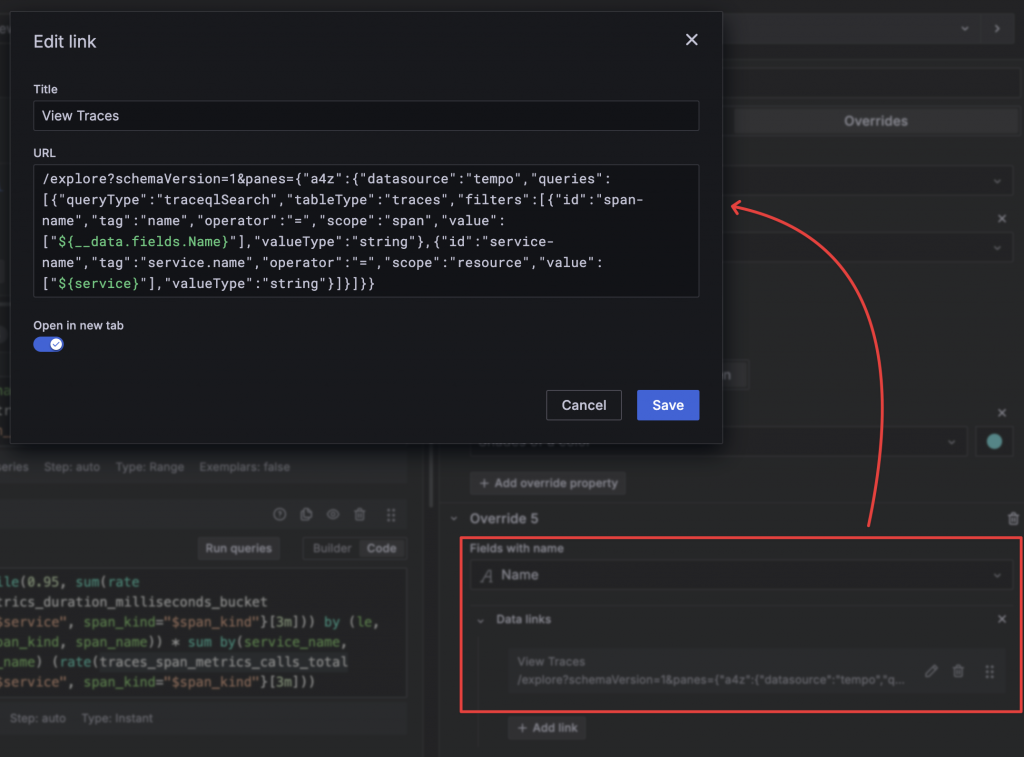
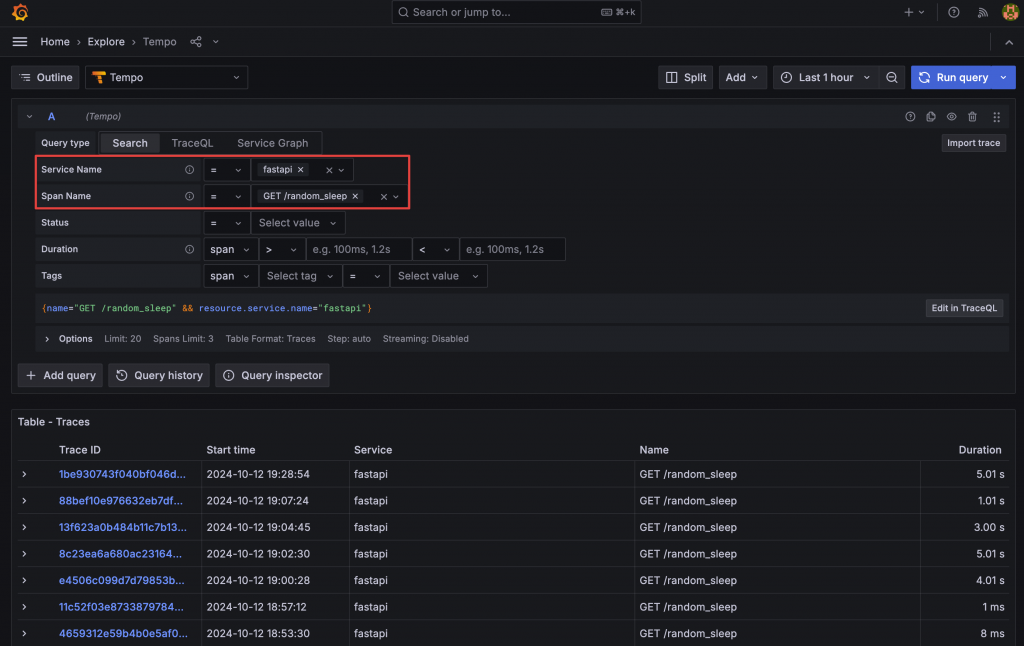
全部完成後,利用 Organize fields by name 和 Overrides 來進行欄位單位、顏色、外觀等細節的調整。
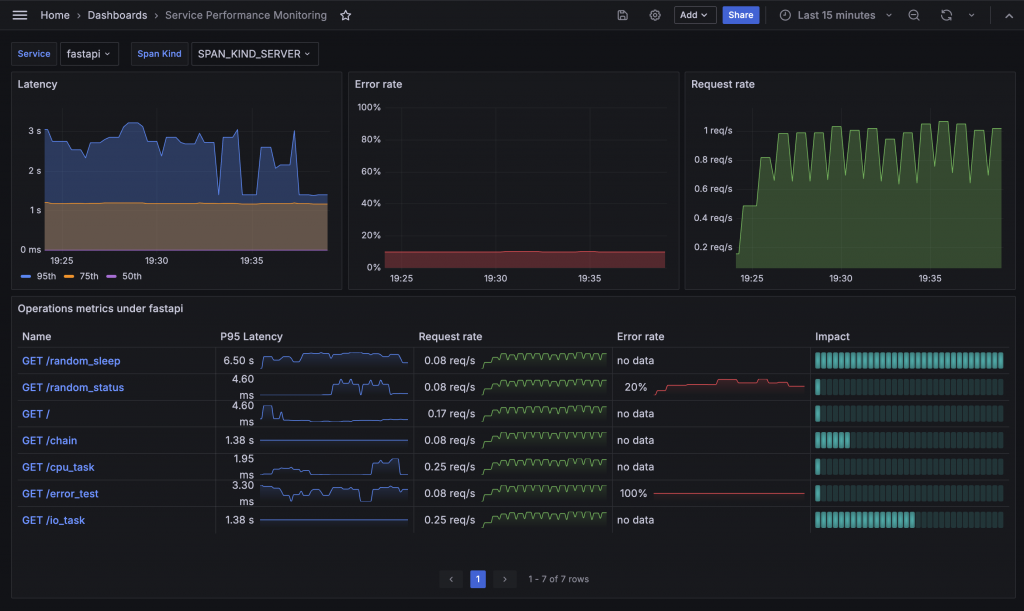
經過這一系列設定,我們成功模仿了 Jaeger 的 SPM,最終的 Dashboard 如下:
範例程式碼:https://github.com/blueswen/grafana-zero-to-hero/tree/main/use-case/otel-spm
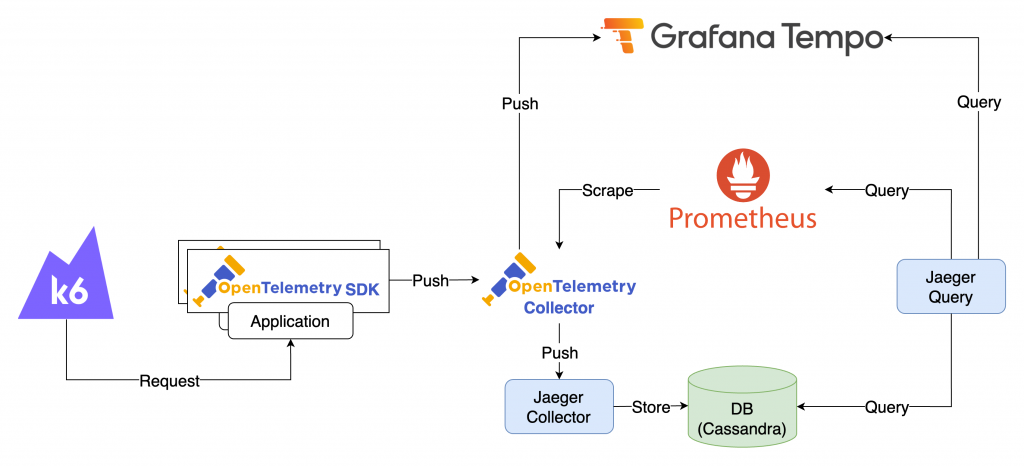
此 Lab 會建立
啟動所有服務
docker-compose up -d
檢視服務
admin/admin
k6/k6-script.js 持續執行對 Applications 發送 Request 60 分鐘,如果已經停止可以透過 docker-compose restart k6 重新啟動關閉所有服務
docker-compose down
在這次的練習中,我們使用了常見的 Prometheus Metrics 方法,例如 rate 計算變化率、histogram_quantile 計算百分位數等,Grafana 則使用了 Table 的 Sparkline 功能,以及利用 Data Link 連結 Tempo 的 Explore 頁面,並同時帶入查詢參數,提供更好的使用者體驗。
透過這次 Lab,不僅展示了 Grafana 的應用,還理解了各種觀測資料的流向,這對設計監控系統來說相當重要。我們也學習到了 Jaeger、OpenTelemetry Collector、Prometheus 和 Tempo 等元件的功能,並重新設計出新的 Service Performance Monitoring。


 iThome鐵人賽
iThome鐵人賽